Architecture of the Motivational System
Intermediating Perception and Action to Satisfy Needs

There are many things that an organism must consistently do if it wishes to survive. Eating, drinking, sleeping, urinating, defecating, and digesting are all critical to immediate daily survival. Safety against environmental danger and threat from other organisms ranks equally with these basic needs. And if we wish for the species to continue, then reproduction is also essential over a longer time frame. These survival needs induce supporting drives such as hunger, thirst, drowsiness, bladder and bowel urges, arousal, aggression, withdrawal, exploration, curiosity, and sociality that are expressed to varying degrees in different species. I refer to the system that oversees expression and management of these drives relative to perception and motor control as the motivational system, and in this post I will propose a tentative architecture for this system.
Functions and Neural Implementation
What I am calling the motivational system comprises functions from several organs in the brain. These functions include:
The recognition of needs based on the state of the body
Evaluation of stimuli relative to whether they will satisfy needs
Evaluation of stimuli for risk relative to potential success
Prioritization to resolve conflicts among different drives
Decision-making based on recognized needs and evaluated stimuli
Distribution of rewards or punishments based on the state of the body
These functions are distributed in the cerebral anatomy roughly as follows. The hypothalamus evaluates current needs and generates basic drives such as hunger, thirst, urinary urgency, aggression, and mating. The suitability of stimuli for satisfying particular needs appears to involve the orbitofrontal cortex, the amygdala, and the ventral striatum (Martin-Soelch, Linthicum, and Ernst, 2009). Evaluation of the risk presented by stimuli similarly involves the orbitofrontal cortex and the amygdala, but includes adaptation inside the hypothalamus as well, both for fighting and mating (Remedios et al., 2017, Krzywkowski, Penna, and Gross, 2020). Prioritization of conflicting needs appears to happen in the cingulate cortex.
Decision-making in the brain is hierarchical, with low-level decisions made in the hypothalamus subsequent to risk evaluation. In humans (and perhaps other animals), there are additional inhibitory pathways from the prefrontal cortex to the hypothalamus that regulate these low-level decisions. High-level decisions are made in the neocortex, likely through a pathway involving the fusion of what-where streams in the mid-cingulate cortex based on reward and outcome information from the orbitofrontal cortex (Rolls, 2019); this pathway will be discussed below.
The rewards and punishments that ultimately drive behavioral learning are wired in various ways (Cassidy & Tong, 2017). The primary reward circuit seems to be centered in the ventral tegmental area just behind the hypothalamus. It is the main source of dopamine in the brain. The nucleus accumbens in the ventral striatum just beside the amygdala also participates in associating rewards with the attainment of positive stimuli and punishments with the failure to obtain positive stimuli, with the roles reversed for negative stimuli. To perform these tasks, the ventral tegmental area and the ventral striatum are strongly connected with the hypothalamus, and the value of a reward is dependent on the current motivation. Thus, when hungry, the attainment of food has higher reward value than when satiated.
Nonetheless, the emission of basic rewards appears to follow the attainment of desirable stimuli, and although the amount of the reward is modulated by the drives, the reward itself is not caused the drive. So eating provides a reward that is larger if the organism is hungry and smaller if the organism is not hungry, but the reward seems to come from eating, not from having been hungry.
The amygdala is responsible for encoding conditioned rewards so that stimuli can be rewarding if they lead to other stimuli that are rewarding. This process allows for the learning of simple subgoals that guide approach or avoidance behavior, related to the evaluation of risk. Whether a stimulus is rewarding depends on whether it is attainable or not. The orbitofrontal cortex encodes expected rewards for stimuli, and the comparisons between it and the amygdala may drive associational learning of reward.
Thus the motivational system in the brain comprises at a minimum the orbitofrontal cortex, the cingulate cortex, the amygdala, the hypothalamus, the ventral striatum, and the ventral tegmental area. Note that the orbitofrontal cortex and the anterior part of the cingulate cortex are part of the prefrontal cortex; there are other prefrontal areas involved in decision-making and outcome evaluation as well. The overall motivational system is every bit as complex as the perceptual system and the motor system, if not more so, since it is the linchpin that ties the two together. Below, I will attempt to tease out an architecture for at least some of these components.
Dual Learning Pathways
It is important to distinguish the learning of stimulus identity and valence from the learning of actions to obtain the stimulus. I propose that this distinction is crucial learning in the brain, parallel to the separate processing of identity (what) and location (where) in the perceptual system. On the one hand, an object is classified as satisfying a particular need if in fact it does satisfy that need upon attainment. On the other hand, an action is successful if it attains a desired stimulus or avoids an undesirable stimulus. Thus actions and objects are judged differently, and the motor system and the perceptual system are trained separately.
Most machine learning frameworks do not make this distinction; instead they try to learn the value of state-action pairs jointly. This coupling introduces an attribution problem that makes discovery of rewarding actions exponentially less likely. In this joint system, if an action allows the attainment of an object that was believed to be beneficial from afar but turns out to be useless once obtained, then the sequence of actions leading to attainment will be punished, making it more difficult to select the correct action when an actually rewarding object is perceived. Instead, the system that predicted the objected should be punished, but the action that obtained it should be rewarded.
In the brain, the separation between identity and action is the familiar what-where distinction proposed by Goodale and Milner (1992). Rolls (2019) has proposed a further elaboration of this theory. I am not sure how much of this elaboration is purely his, but the elaboration is elegant. The what pathway leads from the sensory cortices through the temporal association area. The egocentric where pathway leads from the sensory cortices to the parietal lobe with an alternate allocentric pathway originating in the entorhinal cortex to the hippocampus and from there to the retrosplenial cortex, where egocentric and allocentric perspectives are fused. I discussed these aspects of the what-where pathway in a prior post.
What Rolls added was to note that the what pathway converges to the orbitofrontal cortex, where object identities are classified according to how they do or do not generate rewards. These rewards or non-rewards are arranged topographically as shown in Figure 1, borrowed from Rolls (2019). Rewarding objects are mapped to the medial orbitofrontal cortex, and non-rewarding objects are mapped to the lateral orbitofrontal cortex.

Figure 1. The encoding of pleasant and unpleasant stimuli in the orbitofrontal cortex. Left side shows the ventral (bottom) surface of the brain. Right side shows a section along the midline with the rostral (front) end of the brain to the right. Taken from Figure 4 of Rolls (2019). Taste: 1, 2; odor: 3–10; flavor: 11–16; oral texture: 17, 18; chocolate: 19; water: 20; wine: 21; oral temperature: 22, 23; somatosensory temperature: 24, 25; the sight of touch: 26, 27; facial attractiveness: 28, 29; erotic pictures: 30; laser-induced pain: 31.
To emphasize, the orbitofrontal cortex is not measuring the magnitude of rewards in some absolute sense. Rather, it sorts out different kinds of rewards, grouping pleasant stimuli in the center and unpleasant stimuli at the sides. What we see is a topographical arrangement that classifies the output of the temporal what networks into distinct pleasurable and unpleasurable experiences. Pleasurable smells activate one spot, and attractive faces activate a different one. One often sees in the neuroscience literature a summary statement that “the orbitofrontal cortex identifies predicted reward outcomes”, but this seems to be an oversimplification. The orbitofrontal cortex does not solely compute the magnitude of predicted rewards. Rather, it seems to classify perceived objects according the kind of rewards they predicate.
Once the orbitofrontal cortex has assigned a reward valence to objects, it passes the results to the anterior cingulate cortex. Meanwhile, the where pathways converge at the retrosplenial cortex directly underneath the posterior cingulate cortex. The posterior cingulate cortex receives inputs from the parietal lobe, where action possibilities in response to detected objects. In addition, there are direct connections from the medial orbitofrontal lobe that provide reward information to the posterior cingulate. The anterior and posterior cingulate cortex join together in the mid-cingulate cortex, fusing the what and where streams, with outputs going from there to premotor areas.
The position of the cingulate cortex is worth considering. It forms a half-loop over the top of the corpus callosum in each hemisphere, which is the major connection between left and right hemispheres. The cingulate is uniquely positioned to best integrate information from across the brain, as shown in Figure 2.

Figure 2. The cingulate gyrus (green) and the paracingulate gyrus (yellow). Credit to Daniel Sabinasz, https://commons.wikimedia.org/wiki/File:Cingulate_cortex.gif.
Rolls argues that the anterior cingulate is responsible for selecting among different possible actions that generate different rewards, thus linking actions to outcomes. In particular, the lower part (pregenual) receives inputs from pleasant stimuli and the upper part (supracallosal) receives input from unpleasant stimuli. Thus at least until some stage, the processing of approach and avoidance are streamed separately.
Many other sources beyond Rolls point to the anterior cingulate as the locus of deconfliction, where competing goals are resolved. It has many inputs besides the orbitofrontal cortex, including connections from the hypothalamus, the amygdala, the hippocampus, and the rest of the cingulate cortex.
To clarify the relationship of Rolls’ theory to the dual learning paradigm, we should suppose that decision-making in the motivational system should happen in two stages. First, an object should be selected as a goal to approach or avoid by integrating the current motivational state emanating from the hypothalamus with the attainable objects in the environment as provided by the orbitofrontal cortex and the posterior cingulate. This goal selection would happen in the anterior cingulate cortex. Second, an action should be selected to attain the goal based on information from the parietal lobe and the retrosplenial cortex, mediated through the posterior cingulate. This action selection would occur in the mid-cingulate cortex or thereabouts subordinate to the selected goal.
Rewards governing the adaptation of the motor system should proceed from the success of the action at obtaining or avoiding the goal, which depends on being able to perceive attainment or avoidance. Rewards for adapting the perceptual system should follow visceral satisfaction or attainment of conditioned positive stimuli. It remains unclear how this separation would proceed in biological terms from the lower portions of the motivational system, where rewards originate.
Conditioning the Amygdala
Selecting goals and actions is always contingent on a perceived value. This value is ultimately driven by built-in rewards primarily signaled by dopamine released from the ventral tegmental area and the nucleus accumbens in the basal ganglia. However, complex organisms must take actions that involve multiple steps and might be far removed from the receipt of a direct reward. As an example of this sequential complexity, consider that a predator who wishes to eat must first track an animal, then kill it, then eat it, all before receiving a reward when the food is in its mouth or stomach. Although predatorial behavior is likely supported by a number of instincts, similar action sequences can be trained by attaching indirect rewards to intermediate stimuli, such as the tracks or scent of a prey animal, and thus imbuing these stimuli with value to drive the choice of goal and action.
This need for indirection applies to punishment even more so than rewards; the risk of a mortal punishment should usually supersede a lost opportunity for reward. I will refer to both rewards and punishment as value, with rewards supplying positive value and punishment imposing negative value. The brain largely separates positive and negative valence topographically, as we saw in the orbitofrontal cortex and the anterior cingulate cortex above; the same distinction occurs in subcortical organs between appetitive stimuli with positive valence that reward approach actions and aversive stimuli with negative valence that reward avoidance actions (see Soelch, Linthicum, & Ernst, 2010).
Learning associations between perceived objects and indirect value is one of the major functions of the amygdala, with another role being to initiate responses to anticipated value by triggering bodily responses such as sweating, salivation, hair raising, heart rate or blood pressure increases, and so on. We experience these indirect values as emotions, which we divide into positive and negative reflecting the underlying biology.
The classic psychological term for this associational learning is conditioning, the most famous example being Pavlov’s dogs, who salivated at the ringing of the dinner bell even when no food was present (Pavlov, 1927). There are different kinds of conditioning:
Classical conditioning, in which a stimulus comes to independently generate a specific reaction because it is repeatedly paired with another stimulus that generates that reaction, as in the case of salivating at the sound of a bell;
Evaluative conditioning, in which a stimulus acquires positive or negative valence because of its association with another stimulus that has a known valence, as when mice avoid a place where they lost a dominance battle; and
Operant conditioning, in which the likelihood of a behavior increases or decreases upon cooccurrence with a reward or punishment, respectively (Skinner, 1937).
Referring to the dual learning pathways for action versus object identity mentioned above, it is clear that operant conditioning pertains to action outcomes while the other two pertain to recognizing the value of a stimulus.
There are debates as to whether classical and evaluative condition are in fact different, or whether classical conditioning is simply evaluative conditioning with respect to a stimulus that generates an automatic reaction. Those who say they are different suggest they reflect two learning pathways. To support the claim, there is some evidence that evaluative conditioning is harder to undo than classical conditioning, but that might have to do with the fact of an actual action in the case of classical condition. Personally, I am unconvinced of the difference in terms of implementation at this time.
A Mechanistic Perspective on Motivation
Now let us propose a tentative architecture for representing the motivational system. I want to stress the speculative nature of this proposal, but the parts that are identified here are based on the anatomical review above combined with intuitions about what would be needed to link the perceptual and behavioral systems. A block diagram is shown in Figure 3, with italicized references indicating tentative connections to the underlying neuroanatomy. Figure 3 breaks the motivational system into five subsystems, indicated by the color of the blocks.
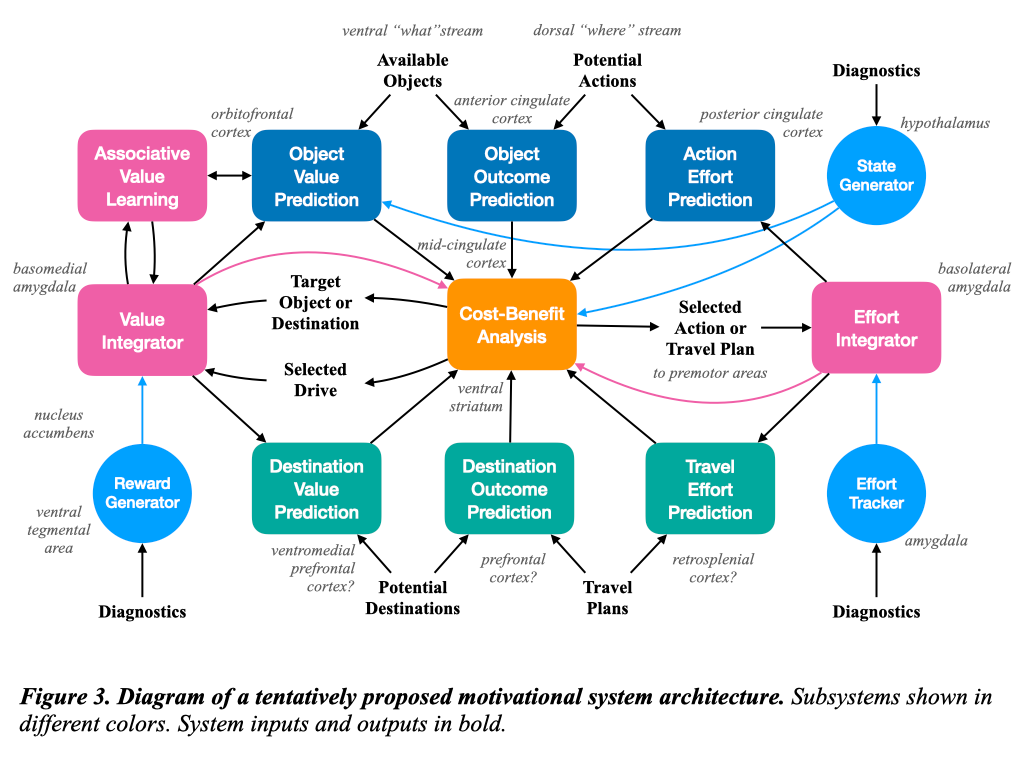
The Diagnostic Subsystem
The first subsystem is the diagnostic subsystem, which receives base level indicators of the health of the organism. The state generator converts diagnostic information into the motivational state, which reports the relative importance of needs to be satisfied. I propose to represent this state as a vector of real numbers with one component for each innate drive. Drives by definition encourage behavior that satisfies needs but do not necessarily map to needs one-to-one; rather, they represent evolved proxy goals. The magnitude of each component of the motivational state represents the degree of reward that would be obtained by satisfying the drive, with zero indicating no reward, positive values suggesting positive reward, and negative values leading to punishment instead of reward.
In addition to the state generator, the diagnostic subsystem includes a reward generator that signals base-level detection of the satisfaction of a need. This system reports rewards and punishments that are non-specific with respect to the need satisfied. Attribution of the reward to specific drives or needs can be performed by higher systems, where the knowledge of the currently active drive is available. Therefore the outputs of this system can be modeled as a scalar number that is positive for rewards and negative for punishment.
The final element of the diagnostic subsystem is the effort tracker, which records the physiological expense of computing the current action for use in assessing cost-benefit tradeoffs. Like the reward, this effort level can be modeled as a single scalar number, in this case nonnegative.
The Value Subsystem
The diagnostic subsystem primarily communicates with the value subsystem, which is responsible for tracking rewards, punishment, and effort, integrating them over time, and associating them to input stimuli.
Its first component is the value integrator, which propagates rewards across short timeframes and associates them to abbreviated input stimuli that are provided both indirectly via the perceptual system and directly via the sensory system. The value integrator essentially performs something like Q-learning from reinforcement learning, but with a primary object in focus to which the propagated rewards apply, represented by the arrow from the target object or place. The rewards and punishments should be temporally discounted to reflect the fact that time delays to rewards make them relatively less valuable.
The value integrator is supported in its associative role by the associative value learning component, responsible for classical and evaluative conditioning based on all available stimuli. This component spreads the rewards received out from a core stimulus to temporally cooccurring stimuli, without losing track of which stimuli are primary and which secondary. This is a form of associative Q-learning that propagates rewards from a primary focus to secondary stimuli, with the propagation discounted for time delay.
The effort integrator sums up the total effort of performing a selected action across systems and over time in order to support cost-benefit analysis.
Both value and effort integrators sum across a session defined by the selection of a particular target and action pair. When this pair changes, the session should be reset and the sums should be zeroed.
The Object Analysis Subsystem
The object analysis subsystem is responsible for evaluating the objects that are currently within perceptual scope and the potential actions on them according to rewards, efforts, and predicted outcome.
The object value prediction component associates each object with an indirect value according to its expected rewards or punishments based on its identity as determined by the what pathway of the perceptual system. Thus we might assess that water is good for thirst, beer is good for hunger and thirst but bad for health, and so on. As the examples suggest, this is a multi-category binary classification task that is highly familiar to any machine learning practitioner. The task is to learn a function that maps object identity representations to a real-valued vector containing estimated log probabilities of satisfying a drive with that object. Larger values indicate high likelihood of drive satisfaction, whereas smaller, more negative values indicate low likelihood. These log probabilities are computed for all available objects to aid in selecting a target.
The predictions of object value should be trained to match the associative values learned in the value subsystem. In this way, the propagated rewards or punishments associated to a primary target can be used offline to train the entire object identity pathway.
Next, the action effort prediction component receives a set of available actions for each object in the perceptual scope via the where pathways of the perceptual system. I suggest that these actions are represented as binary spatial relationships between each body part and each object in scope derived from the egocentric spatial system.
A proposed action necessarily entails a cost. These costs must be factored in when selecting among objects. A less valuable object that can be obtained at low cost may be preferable to an object of high value that requires high cost. The action effort prediction component estimates this cost. The cost should include at a minimum energy expenditure and risk of failure, but may have more dimensions. The effort prediction should be trained to match the actual results coming from the effort integrator in the value subsystem.
Cost and value only matter with respect to outcome. Thus each proposed object and action must be assessed to determine whether the action will attain the object in question. This function is performed by the object outcome prediction component, which should report a probability of successfully acquiring the object as well as an indication of the risk of punishment from obstacles or opponents along the way.
The Destination Analysis Subsystem
When seeking an object to satisfy a drive, there may be no such object in the current perceptual scope. In that case, the correct decision might be to travel to a new place where the object is expected to be in scope. Thus I propose a parallel destination analysis subsystem to mirror the object analysis subsystem but with places in focus instead.
The components of this system behave similarly to their analogues in the object system. The destination value prediction component estimates the reward value of potential destinations. It can be trained to match the outputs of the value integrator. Rather than potential actions based on binary spatial relationships, the destination system must propose a travel plan based on the state of the allocentric map, and this travel plan should be assigned a level of effort by the travel effort estimation component. Outcomes should be assessed by the destination outcome prediction component.
This subsystem is perhaps the most tentative and speculative of the subsystems I propose here. I am unsure whether this system exists separately from the object analysis system. For example, the brain might simply compute place-based value prediction in the orbitofrontal cortex.
However, this choice has the difficulty that actions proposed with respect to objects emerge from the egocentric spatial system as opposed to travel plans, which come from the allocentric spatial system. This separation would suggest that the evaluation of effort and outcomes would have to be distinct for places versus objects, and hence it would make sense for place evaluation to happen elsewhere from object evaluation as well.
A further piece of evidence in support of separate place analysis is that place specifically plays a strong role in the conditioning systems of the amygdala based on extensive experimental data regarding the memory of emotional valence with respect to places. These associations are mediated by substantial connections between the amygdala and the hippocampus. Most people can experientially relate to how places become tightly associated with the good or bad things that happened there.
If the claim that place and value analysis are systemically separate is correct, then the value attribution of places must occur somewhere in the brain. I am uncertain as to where this might be. It has been suggested by Eichenbaum and others that cognition may in fact arise out of place navigation; I discussed this view here. If this view is correct, then evaluation of destination rewards and outcomes may be colocated with or adjacent to areas that engage in cognitive reasoning as an analogue of place navigation.
Cost-Benefit Analysis
The cost-benefit analysis subsystem represents the output of the motivational subsystem. Its role is to combine all value, outcome, and effort proposals in light of the current motivational state to select a drive, a target, and a behavior. This target could be an object or a destination, and the corresponding action or travel plan with minimal effort and optimal outcome would be selected as a behavioral output. The selected target and behavior are chosen to prioritize a current drive, and this drive is likewise an output of the system that can be used to contextualize values, outcomes, and rewards.
The cost-benefit subsystem must also maintain consistency and prevent rapid changes of context. Thus it should prioritize a previously selected target if that target has almost been obtained. The subsystem must also track the changes in target selection to notify the value system that a behavioral session has ended or begun.
Conclusion
To sum up, decision-making in mammals arises out of a core set of drives, and the main business of the motivational system is to bridge perception and action to satisfy these drives under widely varying circumstances.
This post has proven quite difficult to write and perhaps still more difficult to read. However, the issues addressed here are critical to understanding human and artificial intelligence. They also expose potential opportunities to improve current reinforcement learning approaches, which are quite limited in their ability to provide robust credit attribution with respect to perception and action. The specific applications to reinforcement learning are worthy of another post on their own.
For those of you who made it this far, thanks for reading and please leave any comments or questions below! And if you haven’t already, please subscribe to receive updates automatically.
It's interesting to think about these dual learning pathways in comparison of neurobiology and machine learning; I hadn't considered the differentiation much. One of the most enlightening neurosciences courses I had, taught by Dr. Adron Harris was a survey of neuropsychopharmacology - we looked at how various psychoactive substances affected motivation, perception, and behavior and the neural mechanisms underlying each. A common theme was the notion of the "diffuse neuromodulatory systems" and the two most common were the serotonergic diffuse modulatory system and the dopaminergic diffuse modulatory system.
Now, looking back, it's interesting to think about the serotonergic diffuse modulatory system as the perceptual system, ultimately making decisions about the quality of objects, the relative value of them, and how much effort it might be worth to expend on actions directed at those objects. Then the dopaminergic system works in concert to motivate behaviors based on these perceptions.
A key point in thinking about the diffuse modulatory systems is that the receptors for these neuromodulators are *everywhere* in the brain and body - some areas more than others - but diffuse, nonetheless. E.g. SSRI's achieve a significant level of their action in the small intestine, transmitting diffuse modulatory signal up the vagus nerve where brain function is ultimately affected. I imagine these systems working like a symphony playing a concert C and then a concert F ... various instruments throughout the symphony will play (or not) different octaves according to their voicing and the conductor's cue, all coming together in harmony (or experimental jazz, depending on where we are going with the analogy).
Taking this idea a bit further, we have the notion of temporally differentiated signal systems in the body ... hormones are slow, neurotransmitters are fast, etc. Much of hunger and thirst are driven by hormones, which are quite slow, yet they inform perceptions and actions that need to be very fast.
If you take a look at serotinergic and dopaminergic diffuse modulatory systems, I'm curious your thoughts on an analogous reinforcement learning machine ... it seems like both would ultimately serve the same objective function, but to your point, this can lead to big inefficiencies. What would the serotinergic-like objective function be? Perhaps it would be reinforced for clarity of perception?